Spark笔记
1.数据结构方式
RDD是Spark处理数据的数据结构,可以通过两种方式加载数据创建RDD
- 从程序中parallelize一种现有的数据:如Array
- 从外部读取文件:CSV,Hive等
2.RDD操作类型
2.1 RDD的计算方式是lazy加载,即用的时候再计算。
2.2 如果一个变量需要经常使用,可以持久化persist
2.3 封装函数有多种方式:
- 封装静态方法,创建object
- 封装方法以及变量参数等等,创建class
2.3 常用转换方法
| Transformation | Meaning |
|---|---|
| map(func) | Return a new distributed dataset formed by passing each element of the source through a function func. |
| filter(func) | Return a new dataset formed by selecting those elements of the source on which funcreturns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator |
| sample(withReplacement, fraction, seed) | Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. |
| union(otherDataset) | Return a new dataset that contains the union of the elements in the source dataset and the argument. |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in the source dataset and the argument. |
| distinct([numPartitions])) | Return a new dataset that contains the distinct elements of the source dataset. |
| groupByKey([numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, IterablereduceByKey or aggregateByKey will yield much better performance. Note: By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optional numPartitions argument to set a different number of tasks. |
| reduceByKey(func, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral “zero” value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| sortByKey([ascending], [numPartitions]) | When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. |
| join(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| cogroup(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (IterablegroupWith. |
| cartesian(otherDataset) | When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| pipe(command, [envVars]) | Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process’s stdin and lines output to its stdout are returned as an RDD of strings. |
| coalesce(numPartitions) | Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. |
| repartition(numPartitions) | Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. |
| repartitionAndSortWithinPartitions(partitioner) | Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. |
3.创建DataFrame的三种方式
使用toDF函数
使用createDataFrame函数
- 通过文件直接创建
4.scala的vector和spark包中vector不一样
5.Spark优化:(美团Spark)
基础版:https://tech.meituan.com/2016/04/29/spark-tuning-basic.html
高级版:https://tech.meituan.com/2016/05/12/spark-tuning-pro.html
6.Spark保留运行环境(用于查错)
|
|
7.宽依赖和窄依赖
- 窄依赖:指父RDD的每个分区只被一个子RDD分区使用,子RDD分区通常只对应常数个父RDD分区。(map、filter、union操作)。
- 宽依赖:指父RDD的每个分区都有可能被多个子RDD分区使用,子RDD分区通常对应父RDD所有分区。(groupByKey、partitionBy等操作)
- 比较:宽依赖通常对应着shuffle操作,需要在运行的过程中将同一个RDD分区传入到不同的RDD分区中,中间可能涉及多个节点之间数据的传输。
8.ORC格式和PARQUET格式文件对比
impala暂时不支持orc格式的表查询
9.left anti join(某个字段过滤用)
- left semi join —> exists
- left anti join —> not exists
10.Shuffle过程数据倾斜
和Hive中类似,数据的倾斜都发生在shuffle过程中,下面以hive的shuffle进行总结。发生倾斜的根本原因在于,shuffle之后,key的分布不均匀,使得大量的key集中在某个reduce节点,导致此节点过于“忙碌”,在其他节点都处理完之后,任务的结整需要等待此节点处理完,使得整个任务被此节点堵塞。
要解决此问题,主要可以分为两大块:
- 一是尽量不shuffle;
- 二是shuffle之后,在reduce节点上的key分布尽量均匀。
方案总结如下:
解决方案:MapJoin,添加随机前缀,使用列桶表
- mapjoin
|
|
- 手动分割成两部分进行join
|
|
- 当小表不是很小,不太方便用mapjoin,大表添加N中随机前缀,小表膨胀N倍数据
- 使用Skewed Table 或者 List Bucketing Table


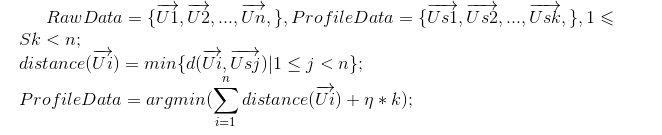


 “间隔”为
“间隔”为










