阅读<白话深度学习与Tensorflow>记
因为前几章都是介绍,不做记录了.近期更新中
1.第四章 前馈神经网络
1.1 概念
- BP神经网络(Back Propagation Networks-反向传播网络)
- RBF Network-径向基函数神经网络
求解凸函数方法:梯度下降法. 凸函数的定义:
把残差函Loss数描述成待定的若干个w所描述的凸函数-Loss(w),那么就可以用梯度下降法,更新w的各个维度,最后找到满足Loss(w)极值点的位置.
2.第五章 手写板功能
直接上手了.
1.传统机器学习与深度学习对比
1.1 传统的机器学习中的监督学习方法概括:
1 朴素贝叶斯
- 实现的是概率量化计算的模型
- 解释:通过对样本的统计,然后算出某件事A发生的概率和某件事B发生的概率之间的量化关系。
2 决策树
- 通过选择合适的维度来增加约束条件降低分类的信息熵。
3 回归模型
- 通过建模和拟合来确定待定系数,通过不断调整待定系数的大小来降低残差的大小,也就是降低模型预测值与训练目标的差距。
4 SVM(支持向量机)
- 通过超平面来分割空间中不同的分类向量,让它们到超平面的距离尽可能远(以保证超平面的鲁棒性)
而深度学习与此不同的是,它通过大量的线性分类器或非线性分类器、可导或不可导的激励函数,以及池化层(卷积网络中会用到这种设计)等功能对观测对象的特征进行自动化的提取。
然而存在的问题:1.在神经网络中,一般网络是比较负责的,如此多的权重值w已经早就没有了统计学中的权值权重的意义,无法得到清晰的物理解释,也无法有效地进行逆向研究。
- 2.这种拥有极高的VC维的网络能够学到很多东西,但这种学习能力通常会导致泛化能力下降。
2.数据集的划分
深度学习中数据的切分:
- 1.训练集:训练得到模型参数
- 2.验证集:用来调整分类器的参数的样本集,在训练过程中,网络模型会立刻在验证集进行验证。用来调整模型参数,我们可以在模型训练过程就可以观察到模型的效果,而不用等到训练结束。并且,有助于验证模型的泛化能力,预防过拟合,是深度学习的标配。
- 3.测试集:测试集则是在训练后为测试模型的能力(主要是分类能力)而设置的一部分数据集合。
第六章 卷积神经网络
1.概念
1.1 同样是一种前馈神经网络,卷积神经网络的两个特点:
- 卷积网络有至少一个卷积层,用来提取特征。
- 卷积网络的卷积层通过权值共享的方式进行工作,大大减少权值w的数量,使得在训练中在达到同样识别率的情况下收敛速度明显快于全连接BP网络。
1.2 用途
卷积网络主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。
2.卷积
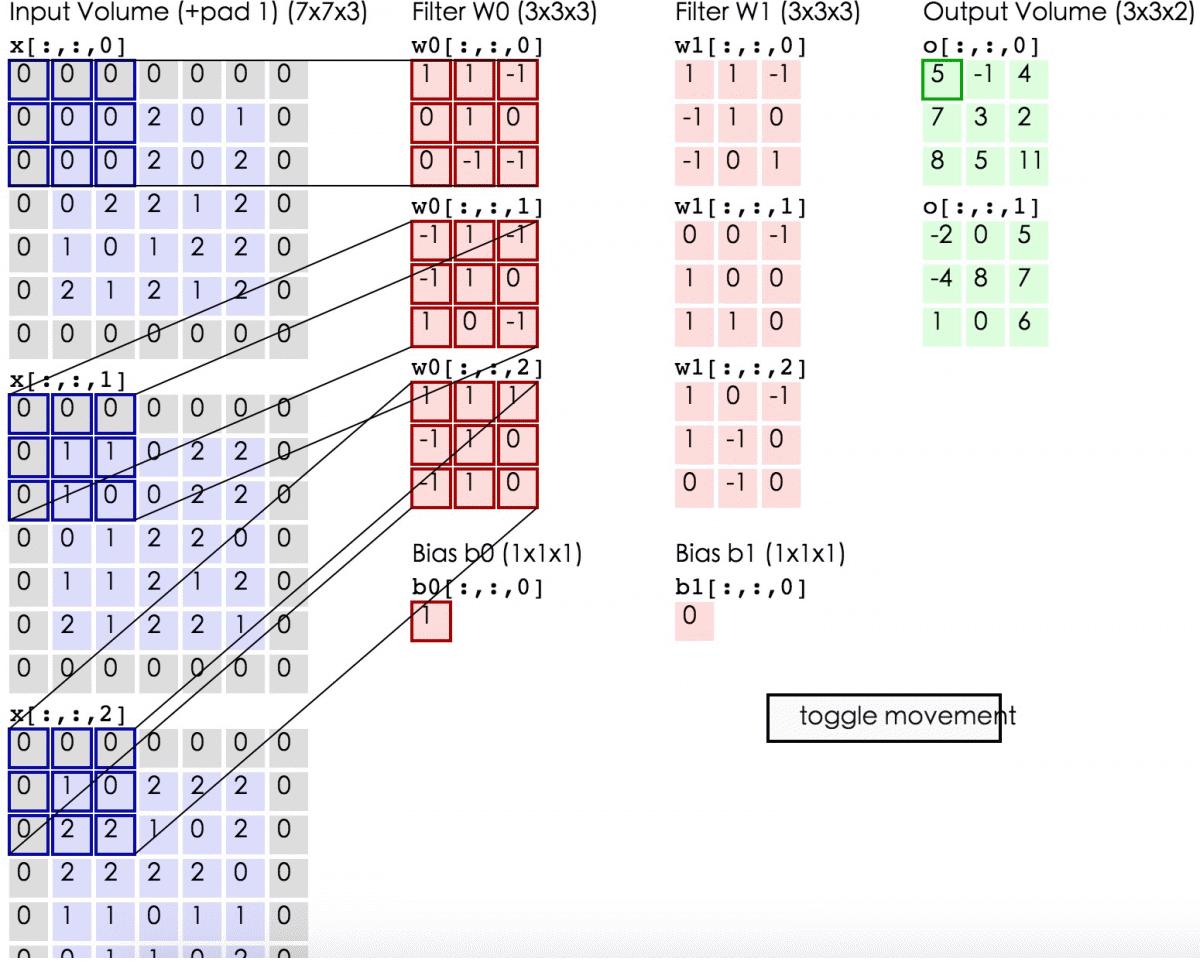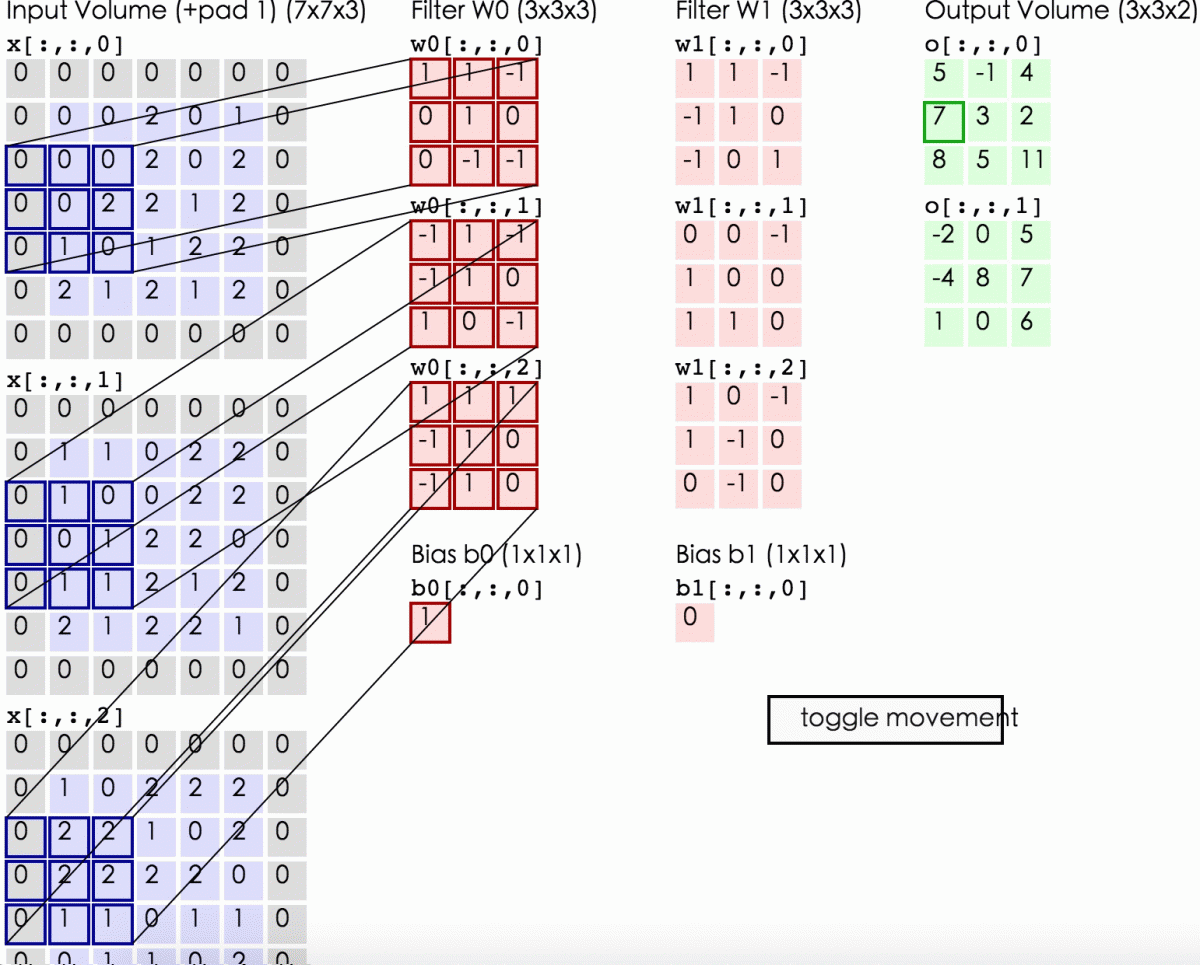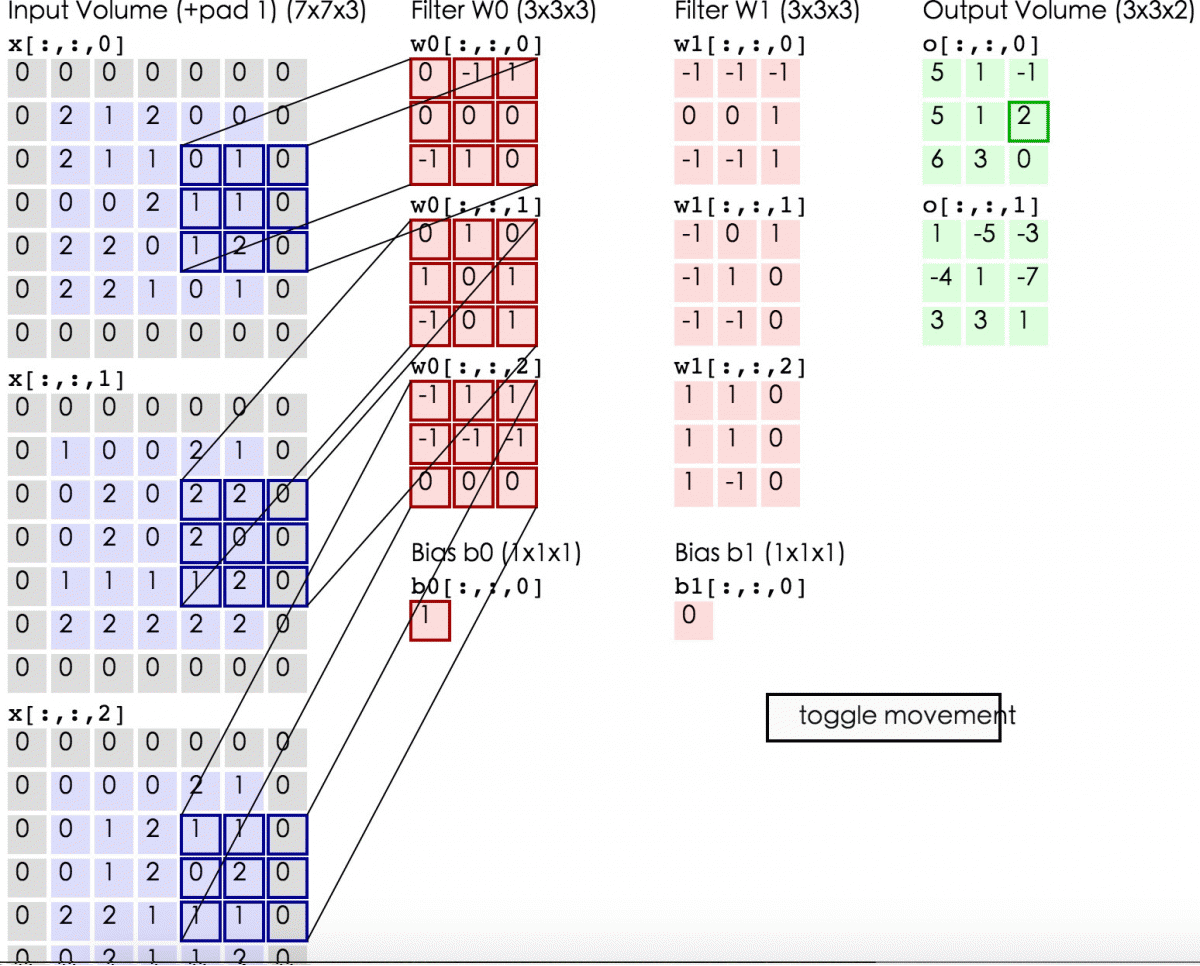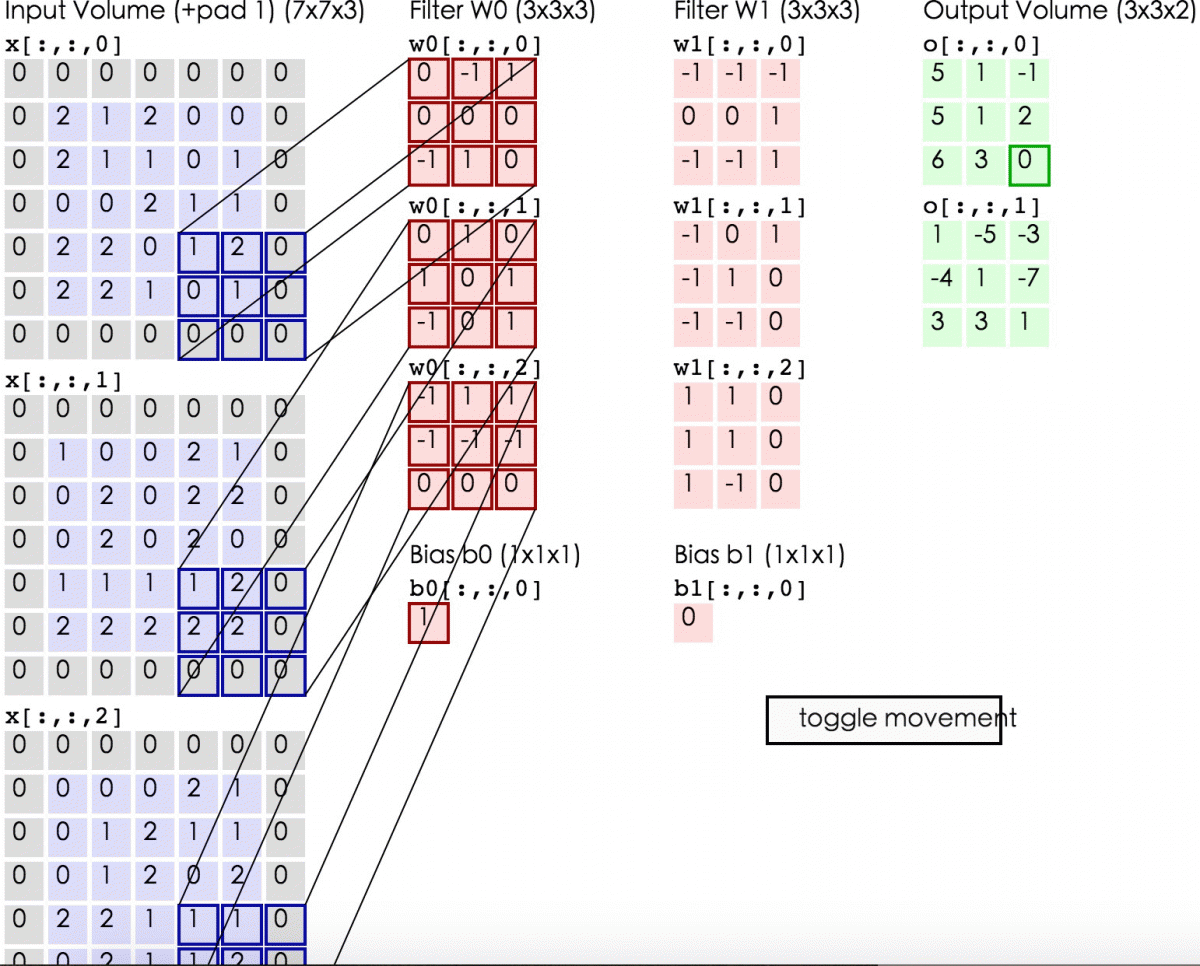
2.1 解释
卷积:在泛函分析中,卷积(convolution)是一种函数的定义。它是通过两个函数f和g生成第三个函数的一种数学算子,表征函数f与g经过翻转和平移的重叠部分的面积。
卷积的数学定义:
从Softmax函数的定义可以看出,最后一层的结点的输出值加和都是1.
4.2 交叉熵
Softmax这种激励函数使用的损失函数看上去比较特殊,叫做交叉熵(cross entropy)损失函数。
5.典型的CNN网络
第七章 综合问题(即一些笼统地都会出现的问题)
本书将这一章安排在第七章,可我总觉这一章貌似应该放在讲完几种神经网络更靠后的位置。
下面罗列一些知识点,供之后再汇过来补充。
- 1.为了加快训练速度,使用GPU并行计算。
- 2.在TensorFlow中指定一个Batch的Size来规定每次被随机选择参与归纳的样本数量,完成随机梯度下降。
- 3.梯度消失问题解决方案:
- 初始化一个合适的w
- 选择一个合适的激励函数(ReLU-“热鲁函数”,Rectified Linear Units-线性修正单元激励函数)
- 4.数据预处理:归一化
- 线性函数归一化
- 0均值标准化
- 5.参数初始化:权值w的初始化。业界比较认可的说法是把整个网络中所有的w初始化成以0为均值,以一个很小的值为标准差的正态分布的方式效果会比较好。即N(0,1)正态分布。
- 6.正则化:在损失函数中加入正则项。带有正则项的损失函数前半部分的损失函数称为”经验风险”,后半部分称为”结构风险”。引入正则化的目的是:防止过拟合。
- 7.其他超参数。什么是超参数:通常指那些在机器学习算法训练的步骤开始之前设定的一些参数值,这些参数没法通过算法本身来学会的。所以,超参的设定可能更多的是经验了。
- 8.DropOut:在一轮的训练阶段丢弃一部分网络节点,在一定程度上降低了VC维的数量,减小过拟合的风险。
第八章 循环神经网络(Recurrent Neural Networks)
1.引入
1.1 隐马尔可夫模型:训练一个HMM模型是比较容易的,输入为:状态序列$X_i$和输出序列$O_i$,得到的模型由两个矩阵构成,一个是状态X之间的表示隐含状态转移关系的矩阵,一个是X到O之间的输出概率矩阵.
2.循环神经网络
2.1 输入:$X_t$向量,输出:$Y$,需要训练的待定系数$W_X$和$W_H$.前面一次的输入缓存在$H_t$中,每次$W_X$和输入$X_t$做乘积,然后与另一部分Ht-1和$W_H$乘积共同参与运算得到$Y$.最后训练得到的就是$W_X$和$W_H$系数矩阵.
2.2 训练过程:传统的RNN在训练过程中的效果不理想,改进后的出现了LSTM算法.
3.LSTM(长短期记忆网络)
3.1 LSTM与传统的RNN网络相比多了一个非常有用的机制,忘记门(forget gate).
3.2 优点:减少训练的时间复杂度,消除梯度爆炸
3.3 构造
- 在t时刻,LSTM的输入有三个:当前时刻网络的输入值Xt,上一时刻LSTM的输出值Ht-1,以及上一时刻的单元状态Ct-1.LSTM的输出有两个:当前时刻LSTM输出值$H_t$和当前时刻单元状态$C_t$.
- LSTM使用门来控制长期状态,门其实就是一层全连接层,输入是一个向量,输出是一个0到1之间的实数(Sigmoid层).
- 当门输出为0时,任何向量与之相乘都会得到0向量,就是什么都不能通过.
- 当门输出为1时,任何向量与之相乘都不会有任何改变,相当于什么都可以通过.
- LSTM前向计算中有三个门
- 遗忘门:用来控制上一时刻的单元状态Ct-1有多少能保留到当前时刻$C_t$
- 输入门:用来控制即时时刻网络的输入$X_t$有多少能保存到单元状态$C_t$.
- 输出门:控制单元状态$C_t$有多少能保留到LSTM的当前输出值$H_t$.
3.4 LSTM和传统的RNN对比:
传统的RNN只有一个状态,对短期的输入非常敏感,而LSTM增加了一个状态C,用来保存长期的状态