1.概念
数据摘要:One of the crucial requirements before comsuming datasets for any application is to understand the dataset at hand and its metadata.[1]
Data profiling is the set of activities and processes to determine the meta-data about a given dataset.[1]总体地说,数据概要可以描述为是能够描述原样本数据的一个子集或者结果.比较简单地一种方式是计算平均值,总和或者统计频率最高的一些值等等方式.而较为有挑战性的是,在多列数据中找出其之间的相互函数或次序依赖等等关系.
传统的数据摘要包括data exploration/data cleansing/data integration.而之后,data management和big data analytics也开始出现.
特别地,因为大数据的数据量大,多样性等特性,传统的技术对于其查询,存储及聚合都是花费高昂的.所以,data profiling在这里就显得非常重要.
Data profiling is an important preparatory task to determine which data to mine, how to import data into various tools, and how to interpret the results.[1]

Data Profiling和Data Mining的比较
1.Distinction by the object of analysis:Instance vs. schema or column vs. rows
2.Distinction by the goal of the task:Description of existing data vs. new insights beyond existing data .
2.动机或用例
Data Profiling的目的:
- Data Exploration
- Database management
- Database reverse engineering
- Data integration
- Big data analytics
3.方法
1.依赖关系数据库,使用SQL语句查询返回结果(不能够找出所有属性列的依赖)
单列和多列分析
2.搜索最优解:启发式算法
启发式算法是一种技术,使得可接受的计算成本内去搜寻最好的解,但不一定能保证所得到的可行解和最优解,甚至在多数情况下,无法阐述所得解同最优解的近似程度.
3.聚类算法—>筛选
4.按每一维动态规划找出子集
4.twitter数据集人物特征选取
- 地理位置特征(反映了用户的时空分布,对于POI的推荐是有用的)
- 活跃度特征(可用于聚类分析)
- 影响力特征(可用于聚类分析)
- 推文特征(反映了用户的兴趣爱好,对于推荐系统是有用的)
- 时域特征
特征处理
1.提取
2.正则化(最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间)
常见的数据归一化方法:
- min-max,对原始数据的线性变换
- log函数转换
- atan函数转换
- z-score标准化
- Decimal scaling小数定标标准化
- Logistic/Softmax变换
- Softmax函数
- 模糊量化模式
特征选取原因:该特征代表了用户的…,对于…工作是有用的.
5.twitter data profiling思路
Motivation
聚类结果的代表性:
Even though the construction of a cluster representation is an important step in decision making, it has not been examined closely by researchers.
度量准则: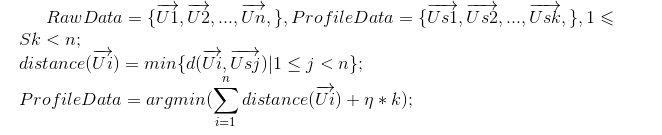
特征提取
直接:location(时区),Followers/Following,category
间接:Activity,Influence,*InterestTags
距离定义
有序属性:闵可夫斯基距离(p=2时为欧式距离)
无序属性:VDM
方法
- 1.聚类方法(LVQ)
- 2.定义图结构来搜索
Challenge-挑战
- a.原集和profile子集的代表性度量准则的定义
- b.ProfileSet的大小,k的确定
- c.寻找ProfileSet(Representation of Clustering[2])
- d.优化搜索算法
5.参考文献
1.Data Profiling-A Tutorial SIGMOD 2017
2.Data Clustering: A Review IEEE Computer Society