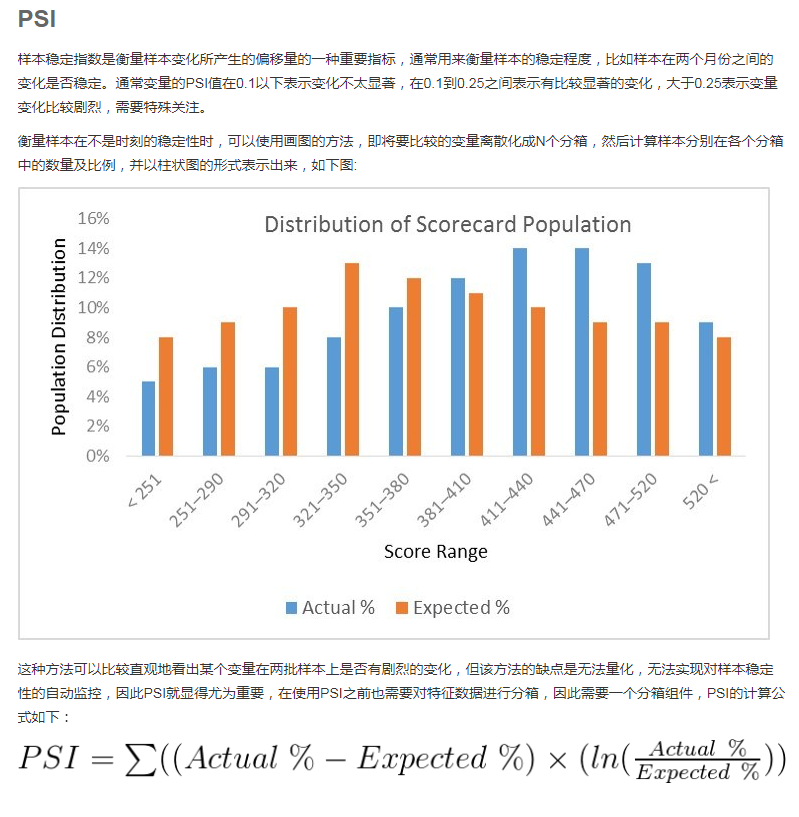
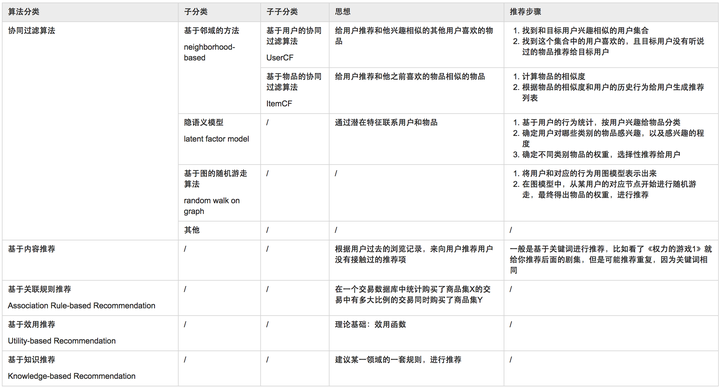
1.网格搜索
网格搜索通过查找搜索范围内的所有的点,来确定最优值。它返回目标函数的最大值或损失函数的最小值。给出较大的搜索范围,以及较小的步长,网格搜索是一定可以找到全局最大值或最小值的。
当人们实际使用网格搜索来找到最佳超参数集的时候,一般会先使用较广的搜索范围,以及较大的步长,来找到全局最大值或者最小值可能的位置。然后,人们会缩小搜索范围和步长,来达到更精确的最值。
2.随机搜索
随机搜索的思想和网格搜索比较相似,只是不再测试上界和下界之间的所有值,只是在搜索范围中随机取样本点。它的理论依据是,如果随即样本点集足够大,那么也可以找到全局的最大或最小值,或它们的近似值。
通过对搜索范围的随机取样,随机搜索一般会比网格搜索要快一些。但是和网格搜索的快速版(非自动版)相似,结果也是没法保证的。
3.基于梯度的优化
4.贝叶斯优化
贝叶斯优化寻找使全局达到最值的参数时,使用了和网格搜索、随机搜索完全不同的方法。网格搜索和随机搜索在测试一个新的点时,会忽略前一个点的信息。而贝叶斯优化充分利用了这个信息。贝叶斯优化的工作方式是通过对目标函数形状的学习,找到使结果向全局最大值提升的参数。它学习目标函数形状的方法是,根据先验分布,假设一个搜集函数。在每一次使用新的采样点来测试目标函数时,它使用这个信息来更新目标函数的先验分布。然后,算法测试由后验分布给出的,全局最值最可能出现的位置的点。
补充: