1.走进JAVA
1.JDK(Java Developmen Kit):将Java程序设计语言,Java虚拟机和Java API类库这三部分统称为JDK.
2.JRE(Java Runtime Environment):把Java API类库中的Java SE API子集和Java虚拟机这两部分统称为JRE.
2.JAVA内存区域与内存溢出异常
先放一张jvm运行时数据区分配情况图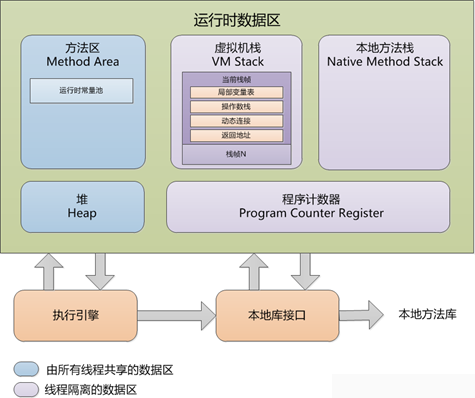
Java堆中分配内存方式:如果Java堆中的内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就是仅仅把那个指针向空闲空间那边挪动一段与对象大小相等的距离,这种分配方式称为指针碰撞(Bump the pointer);如果Java堆中的内存并不是规整的,已使用内存和空闲的内存相互交错,虚拟机就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象,并更新列表上的记录,这种分配方式称为空闲列表(Free List);
划分内存过程需要考虑同步问题,两种方式:1)对分配内存空间的动作进行同步处理(CAS配上失败重试的方式保证更新操作的原子性);2)每个线程在Java堆中预先分配一小块内存,为本地线程分配缓冲(Thread Local Allocation Buffer),当TLAB分配完了之后再做同步操作.
对象的访问定位:使用句柄和直接指针
3.垃圾收集算法
- 标记-清除算法:首先标记出所有需要回收的对象,在标记完成后一次性回收所有被标记的对象.
- 复制算法:将可用内存分为两块,每次只使用其中一块,当着一块内存用完了,就将还存活的对象复制到另一块上,然后把已使用的内存空间一次清理掉.
- 标记-整理算法:首先标记出所有需要回收的对象,让所有存活的对象都向一端移动,然后直接清理掉端界外的内存.\
- 分代收集法:将堆分为新生代和老年代,根据每个代的特点选择合适的垃圾回收算法.
4.垃圾收集器
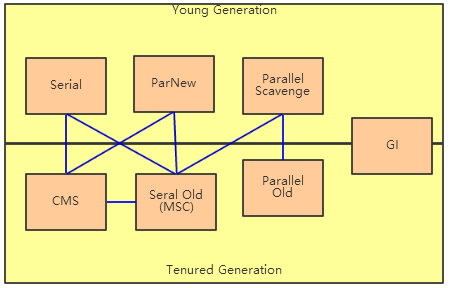
Serial收集器
这个收集器是一个单线程的收集器,但它的”单线程”的意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束.(Client模式下默认的垃圾收集器)ParNew收集器
ParNew收集器就是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集之外,其余行为包括Serial收集器可用的所有控制参数,收集算法,Stop the world,对象分配规则,回收策略等都与Serial收集器完全一样.(Server模式下的垃圾收集器)Parallel Scavenge收集器
Parallel Scavenge收集器更多关注于控制吞吐量(吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)).Serial Old收集器
Parallel Old收集器
CMS收集器
CMS收集器是一种以获取最短回收停顿时间为目标的收集器.目前很大一部分的Java应用集中在互联网站或者B/S系统的服务端上.
CMS收集器是基于”标记-清除”算法实现的,运作过程分为4个步骤:
- 初始标记
- 并发标记
- 重新标记
- 并发清除
- G1收集器
运作大致分为:
- 初始标记(标记GC Roots直接关联到的对象)
- 并发标记(GC Roots可达性分析)
- 最终标记(修正在并发标记阶段标记发生改变的那部分标记记录)
- 筛选回收(对各个Region的回收价值和成本排序)
5.内存对象收集器
1.新生代GC(Minor GC):指发生在新生代的垃圾收集动作,Minor GC非常频繁,一般回收速度也比较快.
2.老年代GC(Major GC/Full GC):指发生在老年代的GC,出现了Major GC,经常会伴随至少一次的Minor GC,Major GC的速度一般会比Minor GC慢10倍以上.
6.虚拟机性能监控与故障处理工具
- jps:虚拟机进程状况工具
- jstat:虚拟机统计信息监视工具
- jinfo:Java配置信息工具(实时地查看和调整虚拟机各项参数)
- jmap:Java内存映像工具
- jhat:虚拟机堆转储快照分析工具
- jstack:Java堆栈跟踪工具
- JConsole和VisualVM(可视化工具)