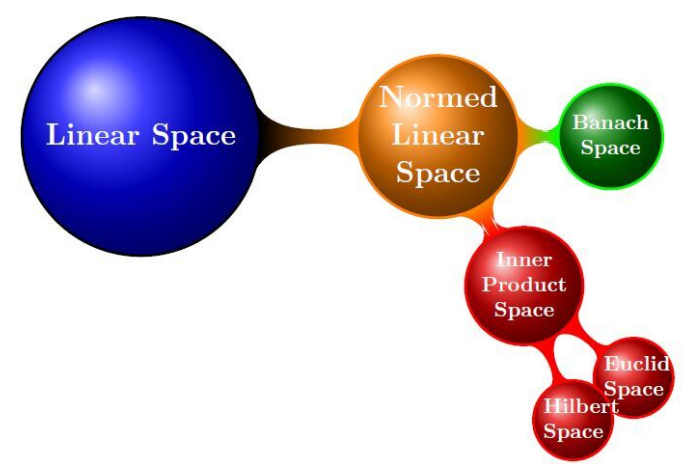
由于论文需要补充数据集,现抓取微博上演员,歌手,导演,运动员和普通用户共1w个.包括他们的基本信息和粉丝和朋友关系.
步骤
(不考虑多线程)
1.安装依赖的库: requests,selenium,BeautifulSoup
2.分析页面,从微博搜索框输入相应领域,获得分页的结果页面,从结果页面提取用户的id.
3.由于返回的结果页面是异步加载,通过selenium模拟浏览器访问,抓取返回的结果页面上的id.(需要对selenium添加请求头信息)
4.抓取到用户id后,可通过weibo API抓取其基本信息和关系信息.
(在抓取用户的关注时,使用多线程)
- 5.python多线程模块threading,因为是I/O密集型,所以用多线程